Commits on Source (51)
-
Per authored
-
Per authored
-
Jorge Aparicio authored
-
Jorge Aparicio authored
the gitlab markdown renderer doesn't seem to like SVG files
-
Jorge Aparicio authored
-
Jorge Aparicio authored
-
Jorge Aparicio authored
-
Jorge Aparicio authored
-
 Henrik Tjäder authored
Henrik Tjäder authored -
Jorge Aparicio authored
-
Henrik Tjäder authored
-
Henrik Tjäder authored
Merge branch 'master' of gitlab.henriktjader.com:d7018e-special-studies-embedded-systems/are_we_embedded_yet
-
Jorge Aparicio authored
-
Per authored
-
Per authored
Merge branch 'master' of gitlab.henriktjader.com:d7018e-special-studies-embedded-systems/are_we_embedded_yet
-
Per authored
-
Per authored
-
Per authored
-
Per authored
-
Per authored
-
John authored
-
John authored
-
Viktor authored
-
Henrik Tjäder authored
claim AES project See merge request !4
-
Henrik Tjäder authored
Update Project_suggestions.md See merge request d7018e-special-studies-embedded-systems/are_we_embedded_yet!3
-
Per authored
-
Per authored
-
Per authored
-
Per authored
-
Per authored
-
Jonas Hedman Engström authored
-
Per authored
-
Per authored
-
Henrik Tjäder authored
-
Per authored
-
Henrik Tjäder authored
-
Henrik Tjäder authored
-
Per authored
-
Per authored
Merge branch 'master' of gitlab.henriktjader.com:d7018e-special-studies-embedded-systems/are_we_embedded_yet
-
Per authored
-
Per authored
-
Per authored
-
Per authored
-
Per authored
-
Per authored
-
Henrik Tjäder authored
-
Henrik Tjäder authored
Merge branch 'master' of gitlab.henriktjader.com:d7018e-special-studies-embedded-systems/are_we_embedded_yet
-
Per authored
-
Per authored
Merge branch 'master' of gitlab.henriktjader.com:d7018e-special-studies-embedded-systems/are_we_embedded_yet
-
Henrik Tjäder authored
-
Henrik Tjäder authored
OpenOCD is from AUR





Showing
- README.md 66 additions, 67 deletionsREADME.md
- assets/cortex-m-layers.png 0 additions, 0 deletionsassets/cortex-m-layers.png
- assets/vscode-build.png 0 additions, 0 deletionsassets/vscode-build.png
- assets/vscode-debug.png 0 additions, 0 deletionsassets/vscode-debug.png
- doc/Ecosystem.md 4 additions, 4 deletionsdoc/Ecosystem.md
- doc/Memory.md 1 addition, 9 deletionsdoc/Memory.md
- doc/Nucleo_64.md 16 additions, 3 deletionsdoc/Nucleo_64.md
- doc/Project_and_grading.md 66 additions, 0 deletionsdoc/Project_and_grading.md
- doc/Project_suggestions.md 64 additions, 0 deletionsdoc/Project_suggestions.md
- doc/Quickstart.md 692 additions, 0 deletionsdoc/Quickstart.md
- doc/RTFM.md 704 additions, 0 deletionsdoc/RTFM.md
assets/cortex-m-layers.png
0 → 100644
{kind=link}
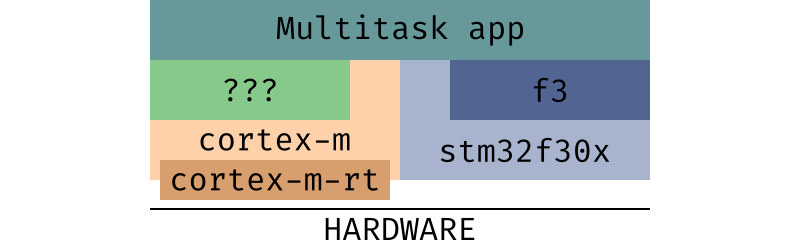
23.6 KiB
assets/vscode-build.png
0 → 100644
{kind=link}
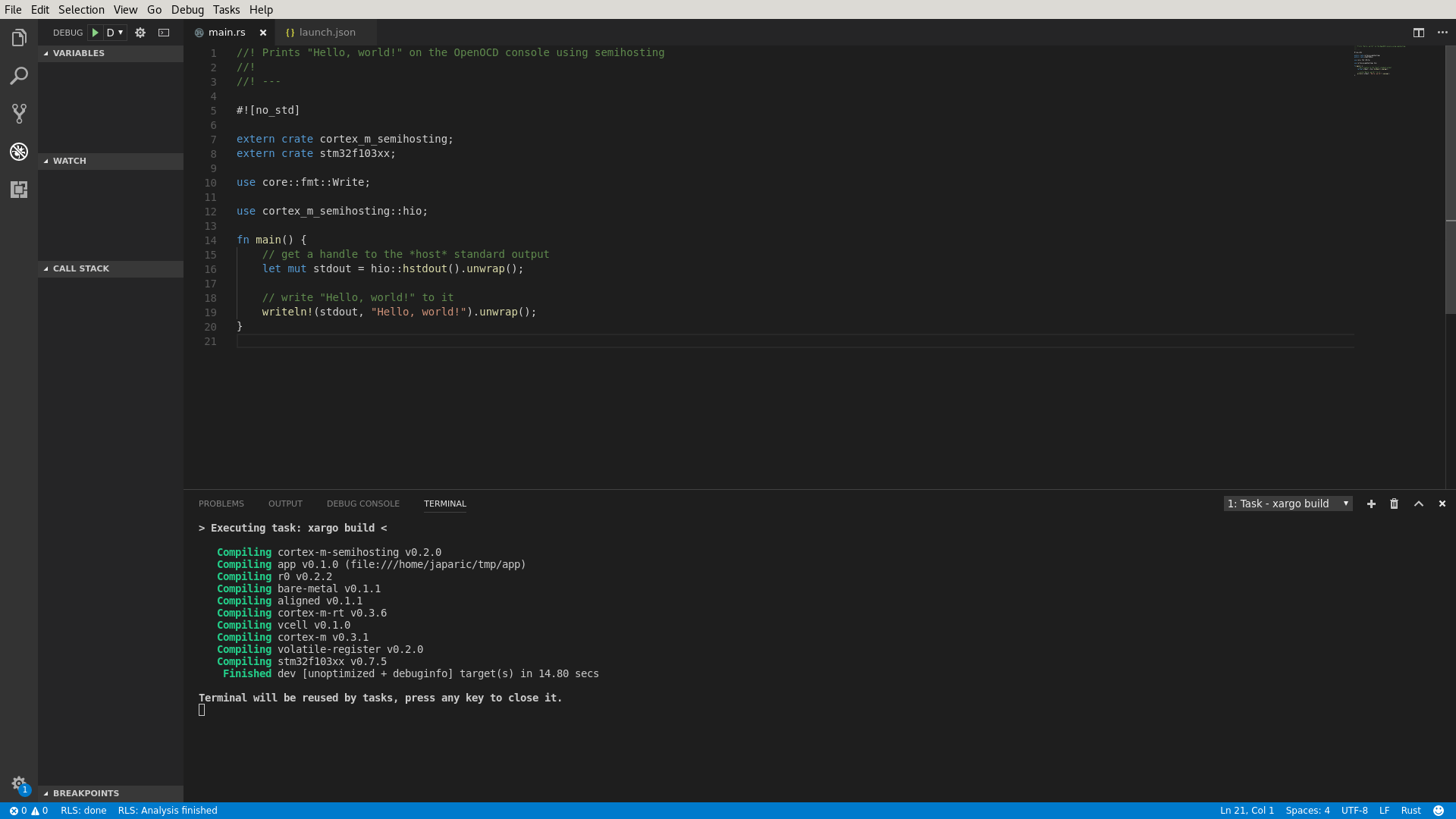
118 KiB
assets/vscode-debug.png
0 → 100644
{kind=link}
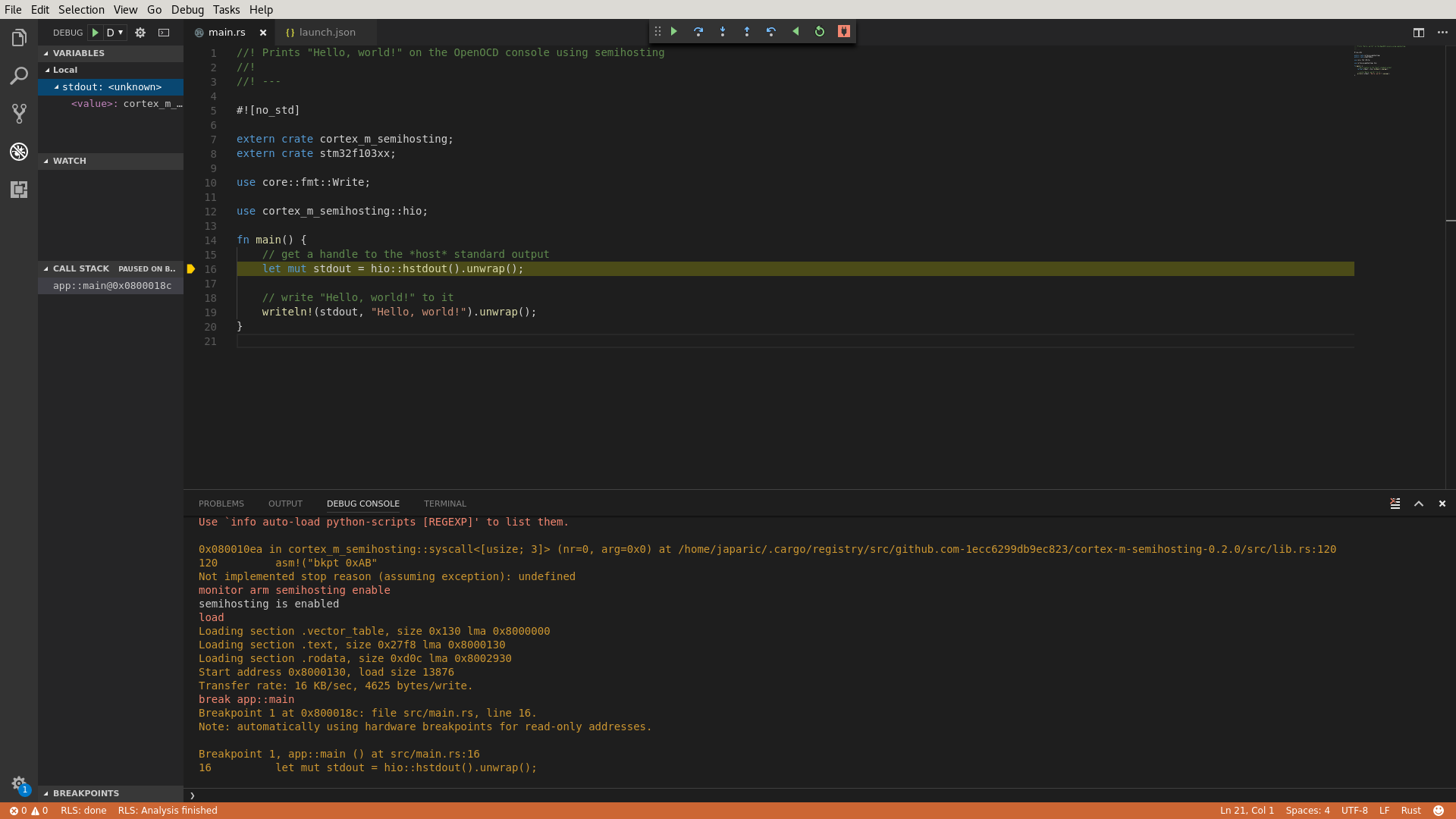
161 KiB
doc/Project_and_grading.md
0 → 100644
doc/Project_suggestions.md
0 → 100644
doc/Quickstart.md
0 → 100644
doc/RTFM.md
0 → 100644